A Quick Primer On Unicode and Software Internationalization Under Linux and UNIX
|

The Unicode (R) Consortium is a registered trademark,
and Unicode (TM) is a trademark of
Unicode, Inc. Linux is a registered trademark of Linus Torvalds.
UNIX is a
registered trademark of The Open Group:. Solaris is a trademark of
Sun Microsystems (now owned by Oracle).
Windows is a registered trademark of
Microsoft Corporation.
|
by Ed Trager
ed dot trager at gmail dot com
Last updated: 2017.07.11.ET
NOTA BENE: I wrote this information a long time ago and now some of it is quite out-of-date.
Nevertheless, there is still a lot of valuable information presented here and so I am keeping this page
available for public consumption as parts of it are still very useful.
This page provides a quick summary of information with links to other URLs
regarding using Unicode for multilingual internationalization projects on
Linux
and other UNIX-based operating systems. If you would like to be
able to use more than one language on your Linux/UNIX computer but haven't
completely figured out how to do that yet, then you should read this page.
I have tested the software and setup configurations
mentioned in this document primarily on Linux (SuSE 7.2, 7.3, 8.1, 8.2, 9.0beta) and,
to a lesser extent, on OpenBSD (3.2, 3.3) and Solaris 8.
The goals of this document are 1) to introduce you to some indispensible
Open Source
software for using Unicode in a Linux or other UNIX environment, and 2) to highlight key
aspects of setting up that software. Other Unicode web resources
cover some of the topics below in much greater depth than here.
Instead of being comprehensive, I have tried to focus on a few key pieces of software
and key configuration issues that will allow you to quickly become productive on your multilingual or
internationalization projects on Linux or other UNIX-based operating systems today. Pointers to
more comprehensive treatments of various topics are provided throughout the document.
Note: This document assumes that you are comfortable working from a command shell
and have knowledge of some basic Linux/UNIX system administration tasks
(such as how to compile and install software from source using the common
./configure --> make --> su -c "make install"
command sequence).
|
|
Computers assign numbers (code points) to represent letters.
There are hundreds of national and ISO standards in existence for computer encoding of modern language scripts.
Many of these legacy encodings are limited to 256 ( i.e., 28 ) code points. This results in numerous problems. A major problem is that 256
code points is often not enough even for a single language, much less multiple languages. A second rather obvious problem is that
code points set aside to represent letters in one national or ISO encoding will unavoidably be re-used to represent completely
different letters in some other national or ISO encoding (For example,
LATIN SMALL LETTER U WITH GRAVE, "ù" in the Western European ISO-8859-1 encoding becomes
LATIN SMALL LETTER U WITH RING ABOVE "ů" in the Central and Eastern European ISO-8859-2 encoding,
GREEK SMALL LETTER OMEGA "ω" in ISO-8859-7, HEBREW LETTER SHIN "ש" in ISO-8859-8 ... and so on! For all the
gory details, read this).
This can easily result in garbled emails, web pages, or databases,
among other things.
For an illustration of the same problem in a slightly different domain, consider a familiar language like English. The language can be written with
just 26 letters, but publishers of English-language scientific and mathematical documents require many additional symbols
--and 256 code points are simply not enough! Imagine how much more problematic electronic information exchange can be for
languages like Chinese where multiple, incompatible encodings exist.
Unicode solves the problems of multiple encodings by assigning unique code points to the letters and ideographs of
all of the world's modern language scripts and commonly used symbols. The Unicode Consortium's page is at
www.unicode.org.
UTF-8 is a serialization method for Unicode that is the de facto standard for encoding Unicode on
UNIX-based operating systems, notably Linux. UTF-8 is also the preferred encoding for multi-lingual web pages.
In this method, ASCII code points occupy one byte. That is, the ASCII subset of Unicode serialized in UTF-8 is
identical to ASCII. Unicode code points in the Basic Multilingual Plane
above the ASCII range are serialized to two or three bytes (additional planes exist in Unicode, which can produce serializations
of up to six bytes).
When characters are serialized to multiple bytes,
the most significant bit is always set, and thus these bytes never fall in the ASCII range. Also, the first byte
of a multibyte sequence representing a non-ASCII character always reserves some bits that indicate how many bytes are used
for the serialization of this character (Fig. 1).

|
|
Fig. 1. UTF-8. When Unicode characters are serialized to multiple bytes in UTF-8, the high bits of the
first serialized byte indicate how many bytes are used for the serialization of that character. The bits represented by "n"s hold the unicode
character code value.
|
This results in a stateless encoding in which missing bytes will be evident. UTF-8 provides a simple and elegant solution
for internationalizing UNIX-based, byte-oriented operating systems and software. For all of the details, read Markus Kuhn's excellent
FAQ, UTF-8 and Unicode FAQ for Unix/Linux.
All of the software mentioned below supports UTF-8 well.
|
Advice: UTF-8 is simple to use, store, and view in documents, databases,
and source code. Use the UTF-8 encoding for all of your multilingual, international, or non-English
data and documents. Avoid using legacy national character encodings
(i.e. ISO-8859-1,ISO-8859-2, ISO-8859-15, TIS-620, shift-jis, gb-18030, KOI8, etc.). There are also good reasons to
avoid using other Unicode encodings, such as UTF-16.
Information on how to convert legacy data to UTF-8 is provided below (see Utilities).
|
|
In order to take full advantage of Unicode on your Linux or other UNIX system, you will need to set your locale to
a UTF-8 locale. Some recent distributions of Linux now default to using a UTF-8 locale by default.
However, unless you are using a very recent Linux distribution, you are still very likely using a legacy locale based
on ISO-8859 or other national encoding.
If you are using some UNIX-based OS other than Linux, it is even less likely that you are already using a UTF-8 locale.
To determine your current locale settings,
type locale. Here are some results from Linux and Solaris:
|
"locale" example from Linux:
|
user_a@some_linux_box:~> locale
LANG=en_US
LC_CTYPE="en_US"
LC_NUMERIC="en_US"
LC_TIME="en_US"
LC_COLLATE=POSIX
LC_MONETARY="en_US"
LC_MESSAGES="en_US"
LC_PAPER="en_US"
LC_NAME="en_US"
LC_ADDRESS="en_US"
LC_TELEPHONE="en_US"
LC_MEASUREMENT="en_US"
LC_IDENTIFICATION="en_US"
LC_ALL=
|
|
|
|
"locale" example from Solaris:
|
user_b@some_sun_box:~> locale
LANG=
LC_CTYPE="C"
LC_NUMERIC="C"
LC_TIME="C"
LC_COLLATE="C"
LC_MONETARY="C"
LC_MESSAGES="C"
LC_ALL=
|
|
|
All UTF-8-based locale settings end in "UTF-8", so it is evident that neither user_a nor user_b in
the examples above is using a UTF-8 locale. To determine what other locale settings are available to you, type
locale -a:
|
"locale -a" example from Linux:
|
user_a@some_linux_box:~> locale -a
C
POSIX
af_ZA
ar_AE
ar_BH
ar_DZ
ar_EG
ar_EG.utf8
ar_IN
. . .
uz_UZ
vi_VN.utf8
yi_US
zh_CN
zh_CN.gb18030
zh_CN.gbk
zh_CN.utf8
zh_HK
zh_TW
zh_TW.euctw
zh_TW.utf8
|
|
|
|
"locale -a" example from Solaris:
|
user_b@some_sun_box:~> locale -a
POSIX
C
iso_8859_1
|
|
|
It's evident that the Linux distribution (SuSE 7.3 was used for the example) has many UTF-8 locales installed by default
(not all are shown), while the Solaris box has none. At the time of this writing,
Solaris did provide UTF-8 locales, but they could be installed as optional packages:
see the Solaris Internationalization Guide.
To change your locale setting in Linux, just set the LANG environment variable in
your .profile file.
Note that the output from locale -a on the Linux box shown above shows
"utf8"
in lower case without a hyphen: this is a BUG. When you set the LANG variable,
be sure to type UTF-8 in UPPER CASE and with a hyphen:
|
Setting the LANG variable in a .profile file for the BASH shell under Linux:
|
...
export LANG=en_US.UTF-8
|
|
When you log back in using the new LANG setting,
you should now see that many of the other "LC_" locale environment
variables have been updated automatically:
|
After setting LANG to a UTF-8 locale in Linux:
|
user_a@some_linux_box:~> locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE=POSIX
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
|
|
Under a UTF-8 locale, you can now take full advantage of Unicode on your machine. Note however, that some Unicode
software can be used quite effectively even if you cannot, or are not yet ready, to change to a UTF-8 locale. For example,
Yudit, described below, will work just fine even on systems such as OpenBSD which currently do not support
different locales.
Even in these days of KDE and Gnome,
no Linux or UNIX aficionado would want to live without a good terminal emulator. Several Unicode-enabled terminal emulators are
described below.
Mlterm is arguably the best terminal emulator for
multilingual work and is certainly my favorite (Fig. 1).
When compiled with fribidi and
libind, mlterm supports complex Indic scripts like Devanagari, Indic-derived scripts like Thai, and
right-to-left scripts like Arabic and Hebrew. Mlterm also sports a GTK+-based GUI configurator
which is activated using the rather unusual CTRL-<RIGHT MOUSE CLICK> combination (Fig. 2).

|
|
Fig. 2. Mlterm. A GUI configurator makes it easy to set up mlterm.
An HTML file encoded in UTF-8 is being viewed in vim under mlterm.
|
By default, Mlterm uses a bitmap font, usually GNU Unifont which is
pre-installed on most Linux distributions and other free Unices. GNU Unifont
is the bitmap font shown in Fig. 2 above.
If you want, you can also have Mlterm use an anti-aliased TrueType font.
In this case, a monospaced font like Bitstream Vera Sans Mono or
Everson Mono Unicode is best. You will need (probably as root) to modify Mlterm's $PREFIX/etc/mlterm/aafont configuration file to indicate which fonts you want to use
to display normal and double-width CJK characters ($PREFIX depends on where Mlterm is
installed. If you installed it yourself, it is probably /usr/local/. If Mlterm came
preinstalled, it is probably just /etc. As an example, here is
what my aafont file looks like:
ISO10646_UCS4_1=Everson Mono Unicode-iso10646-1;
ISO10646_UCS4_1_BIWIDTH=Bitstream Cyberbit-iso10646-1;
This specifies that Everson's sans-serif Everson Mono Unicode font be used
for normal width characters while the serif Bitstream Cyberbit font be used
for double-width CJK characters. In order to toggle anti-aliased fonts, I need to
start Mlterm with the -A flag, like this:
mlterm -A &
Here is what the result looks like on a Mandrake Linux box:
 If you want to use a variable-width font, then after modifying
If you want to use a variable-width font, then after modifying aafont
appropriately, start Mlterm like this instead:
mlterm -A -V &
Note: You might need to become root in
order to compile libind. The problem appears to be in the supplied Makefile. You can
either fix the Makefile, or you can remain lazy and just become root.
|
|
A second alternative is to use xterm (Fig. 3) which is supplied with XFree86.
Xterm does not support right-to-left languages like Arabic or Hebrew. I don't think it supports most Indic
scripts. It does support Thai though, as shown in Fig. 3 below.
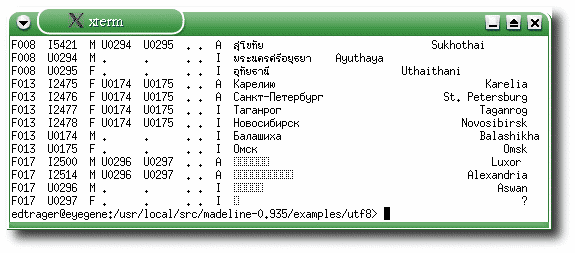
|
|
Fig. 3. Xterm in UTF-8 mode. Xterm supports UTF-8, including Thai, but not right-to-left languages like Arabic.
|
For both mlterm and xterm, you will need to set your locale to a UTF-8 locale.
When I use an account or a machine where the locale is not a UTF-8 locale, I use the following
"mini scripts" for starting mlterm and xterm for multilingual work:
|
"uterm" script for starting mlterm with UTF-8 support when the locale has not yet been set to UTF-8:
|
#!/bin/sh
LC_CTYPE=en_US.UTF-8 mlterm --sbmod=right &
|
|
|
"uxterm" script for starting xterm with UTF-8 support when the locale has not yet been set to UTF-8:
For xterm you must
specify the font on the command line which is very inconvenient unless you use a script or alias
to start the thing:
|
#!/bin/sh
LC_CTYPE=en_US.UTF-8 xterm -u8 -fn \
'-misc-fixed-medium-r-semicondensed--13-120-75-75-c-60-iso10646-1' &
|
|
|
Note: OpenBSD 3.2 does not appear to
have locale support, so these scripts produce a "locale settings failed" message. Despite that, simple utilities like UNIX
cat do work correctly and produce readable displays of UTF-8 files on OpenBSD. However, other software such as
vim fails to work correctly in the absence of locale support from the operating system, despite the capabilities of the terminal
emulator.
|
|
Although I like the features of KDE's Konsole
(KDE 3.x), I have noticed annoying bugs when rendering Thai and Arabic scripts under a UTF-8 locale,
so I refrain from recommending it for multilingual work at this time.
A number of good unicode editors are now available for Linux/Unix, but here I am only going to describe three:
Yudit (Fig. 4) is an indispensible unicode text
editor for the X Window System. Yudit can be used under any locale setting. It can even be used on OpenBSD
which lacks locales. The program is extremely easy to use
and comes with a large number of keyboard maps -- and even handwriting recognition for Kanji and Hanzi.
Handwriting recognition is an excellent idea, but in practice it only works well for fairly simple characters
with few strokes, like "人" or "水", as drawing more complex characters with a mouse is too tedious.
For serious Chinese, Japanese, or Korean (CJK) typing tasks,
an input method engine such as SCIM (discussed below) is required.
Besides the editor itself,
the program distribution includes two absolutely indispensible utilities:
uniprint provides Postscript-based printing.
Uniprint can be used for printing from within Yudit,
or from the shell.
uniconv seamlessly converts files between a large
number of Unicode and legacy national and ISO standard encodings.
Information on using uniprint and uniconv are
provided below under Utilities.
Program menus are available in many languages. The program has few external dependencies (other than X Windows itself)
and there is no need for any pre-installed multi-lingual locale environment. For example, Yudit works perfectly
on OpenBSD 3.2 which lacks locale support, where vim fails.

|
|
Fig. 4. Yudit comes with pre-installed keymaps for numerous languages. The program and its
accompanying utilities, uniprint and uniconv, are must-have tools in your Unicode toolkit.
|
Many professional developers are already addicted to using vi as their editor of choice, so it is nice to
know that the popular implementation vim fully supports UTF-8 (Fig. 5).

|
|
Fig. 5. Vim running in mlterm with color syntax highlighting for C/C++. In the code
shown here, the static C-style strings directly contain UTF-8 encoded locale data.
|
There are two keys to making console-mode vim useful for multilingual work. First, you must run vim in a UTF-8-capable
terminal emulator like mlterm. Secondly, you are going to need keyboard maps for inputting languages of your choice.
Unlike Yudit, numerous standard keymaps do not appear to be distributed with vim.
To determine what keymaps are available, enter the following vim command:
:echo globpath(&rtp, "keymap/*.vim")
This tells you the location of the globally available keymaps, as well as the path where
you'll want to place any keymaps that you create if you want to make those maps available to all users.
Setting up and using a keyboard map for vim is not difficult. An excerpt from a Thai
keyboard map is shown below. The conventions for naming a keyboard map file are:
<language>_<encoding>.vim
So, in this case, the file will be called:
thai_utf-8.vim
Here's an excerpt from the file:
|
Example vim keyboard map:
An excerpt from thai_utf-8.vim is shown below.
|
" Vim Keymap file for UTF-8 Thai
" Maintainer: Edward H. Trager <ehtrager@umich.edu>
" Last Updated: 2003-04-08.ET
"
" This mapping adheres to the Thai standard TIS820-2538 keyboard
" layout.
let b:keymap_name = "thai"
loadkeymap
~ ๛
! ๅ
@ ๑
# ๒
$ ๓
% ๔
^ <char-0x0E39> " THAI CHARACTER SARA UU
& <char-0x0E4E> " THAI CHARACTER YAMAKKAN
. .
. .
. .
|
|
Comment lines in a keyboard map begin with a quotation mark, '"'. The line,
"let b:keymap_name = "thai"" provides a short name for the
map so that we can issue a command in vim to use this map like this:
:set keymap=thai
Everything on the lines following the word "loadkeymap" represents
the keyboard mapping. One or multiple keys can be specified in the first column as the keys to type. One
or more bytes can be specified as the result in the second column.
For example, as shown in the excerpt above, the first six key mappings from the
beginning of the top row of a QWERTY keyboard are mapped directly to the
Thai characters which have been serialized as UTF-8. Each of these characters actually
requires three bytes, but they appear as the Thai characters in your web browser. The fastest
way to create a keymap like this is to use Yudit, which is exactly what I did.
The next two entries show an alternate approach: here the unicode code points are entered directly in
hexadecimal which can be typed in simple ASCII using any editor you like. The unicode code points for any script can be obtained
online in portable document format (PDF) from www.unicode.org/charts/.
After you have created a keyboard map and placed it in the appropriate location (for example,
/usr/share/vim/current/keymap), from within vim simply
type:
:set keymap=thai
...to enable this alternate keymap. When you are in insertion mode, you can toggle between the
standard and alternate key maps using CTRL-^.
Finally, just to give you an idea of what else you can do, here a short excerpt from a custom keymap file
which uses pinyin romanization to specify some Chinese characters. This example simply demonstrates how a series of
multiple keystrokes can be mapped to unicode characters:
|
Another example vim keyboard map:
An excerpt from a special map that uses pinyin spellings
for entering some Chinese characters:
|
" Custom pinyin keymap
" Maintainer: Edward H. Trager <ehtrager@umich.edu>
" Last Updated: 2003-04-08.ET
"
let b:keymap_name = "special"
loadkeymap
ri 日
shui 水
ni 你
ren 人
xin 心
zhu 竹
. .
. .
. .
|
|
Note that you can specify a keymap to use in your .vimrc file, as the following example shows:
Example ~/.vimrc file:
This .vimrc file specifies an alternate keymap
which can be toggled using CTRL-^. The other
lines set up vim for C/C++ color syntax highlighting
and automatic indentation.
|
set nocp incsearch
set cinwords=if,else,while,do,for,switch,case
set cindent
set nowrap
set keymap=thai
syntax on
|
|
For a complete treatment of using Unicode and keymaps, from within vim type:
:help mbyte.txt
:help mbyte-keymap
Mined is a console-mode unicode editor with an intuitive user interface, pull-down menus,
extensive Unicode support, including double-width and combining characters, Arabic ligature joining,
keyboard mapping, syntax highlighting, and many other features. Mined can be used on UNIX and
DOS/Windows platforms.

|
|
Fig. 6. Mined is another unicode editor.
|
I have not personally used mined, but it appears to have a nice feature set.
For a more extensive review of Unicode editors, see Alan Wood's summary,
Unicode and Multilingual Editors and Word Processors for Unix and Linux.
Keyboard maps are insufficient for typing Chinese, Japanese, and Korean (commonly
referred to as "CJK"), as well as other languages such as Tibetan.
These languages require sophisticated software input methods (IMs).
One of the best among the set of Open Source IM engines at the time when this document was originally written was
Smart Common Input Method (SCIM)
, which I describe below.

|
James Su's
Smart Common Input Method (SCIM)
is a Unicode-based IM platform written in C++.
For users, SCIM is an excellent choice because it is simple to set up and use in a UTF-8
or legacy locale.
For software developers, it is also nice because
it abstracts input method interfaces into a set of simple, independent classes
so developers can write their own input methods easily in a few lines of code.
|

|
|
Fig. 7. SCIM is an excellent IM application with support for a number
of CJK input methods, including
自然码zìránmǎ
which is shown being used
to enter Chinese for a Google search in Mozilla.
|
SCIM currently provides input tables for at least the following
methods:
- Japanese hiragana
- Japanese katakana
- Korean hangul 한글입력
- Korean hanja 漢字입력
- Chinese Cangjie 倉頡
- Cantonese guangdong pinyin 廣東拼音
- Chinese erbi 二筆
- Chinese jyutping 粵語拼音
- Chinese simplex 簡易
- Chinese wubi 五筆字型
- Chinese zìránmǎ 自然碼
- Chinese intelligent pinyin 智能拼音
Of the numerous Chinese input methods available, intelligent pinyin and ziranma
are the easiest to use.
The keyboard layout and a description of how to use the
自然碼 zìránmǎ, or 自然双拼 zìrán shuāngpīn, method
can be found here.
Note that the intelligent pinyin method is closed-source software, but you can
install a binary RPM version for use with SCIM free of charge. If you are compiling from
source, I think you will find the supplied 自然碼 zìránmǎ method quite satisfactory.
SCIM requires atk-1.0+, glib 2.0+, pango-1.0+, and gtk+2.0+.
These libraries will be present in newer Linux distributions, or you can download them
from the GTK+ site
here.
After compiling SCIM, you will need to add the following lines to your
.xinitrc file in order to have SCIM start
whenever you start X windows:
Example lines to add to ~/.xinitrc file for starting SCIM:
The first line starts scim as a daemon. The second line tells X to use SCIM as
the input method server.
|
scim -d
export XMODIFIERS=@im=SCIM
|
|
If you are using an older version of SCIM (prior to version 0.8.0) and are not already running in a Chinese, Japanese, or
Korean locale, then you will need to set the LC_CTYPE environment
variable to refer to a Chinese, Japanese, or Korean locale in your
~/.profile file.
Note that you can do this even if your LANG
environment variable is set to another (UTF-8) locale, such as English, as shown in the
example below. Versions of SCIM after v. 0.8.0 will work fine with LANG
set to any UTF-8 locale.
Example lines to add to ~/.profile file for starting SCIM:
Versions of SCIM prior to v. 0.8.0 expect to operate in a CJK environment. However, you
can have SCIM operate under another primary language environment, such as UTF-8 English,
by setting the LANG and LC_TYPE environment variables in the manner shown
here. This example assumes you are using the BASH shell. With versions of SCIM after
v. 0.8.0, any UTF-8 locale will do and you won't need to set LC_CTYPE separately.
|
export LANG=en_US.UTF-8
export LC_CTYPE=zh_TW.UTF-8
|
|

|
Mutt is an excellent email agent with
good UTF-8 Unicode support. Mutt can also be extensively customized to meet your individual needs.
For example, a very simple customization is to have emails from certain people, domains, or mailing lists
highlighted in special colors in the message index. An example of this is shown in the image on the left below
(Fig. 8). Another feature I like about Mutt is that you can use any editor you want to compose
your emails. I have Mutt set to use Yudit for composing email in UTF-8.
A more common choice is to use Vim as the editor.
Once you have used Mutt a few times and started to play around with its various configuration
options, you'll never go back to using another email agent again!
|

|

|
|
Fig. 8. Mutt is an excellent email agent. Once you have used Mutt a few times and customized
it to your liking, you'll never want to use any other email agent! Left side: Message index displayed
in Mutt with color customizations running in a KDE konsole terminal.
Right side: Mutt displaying a UTF-8 encoded message in mlterm.
|
This section lists conversion and printing utilities.
For converting a file from one encoding to another, three utilities are worth mentioning here:
iconv which is part of GNU libc (and hence probably already on your system).
uniconv which is distributed with Yudit
convmv.
Usage of these utilities is described below.
GNU iconv has knowledge of a huge number of encodings, although the authors warn that
"this does not necessarily mean that all combinations of these names can be used for
the FROM and TO command line parameters". To get a list of all known encodings, type:
iconv -l
Usage is as follows:
|
iconv -f <from_encoding> -t <to_encoding> [-o <output_file>] <input_file>
|
% iconv -f ISO8859-8 -t UTF-8 -o myfile.utf8 myfile.input
|
|
Uniconv is distributed with Yudit and understands a useful range of internal and external encodings.
For a complete list, type:
uniconv --help
Usage is shown below:
|
uniconv -decode <from_encoding> -encode <to_encoding> -in <input_file> -out <output_file>
|
% uniconv -decode java -encode utf-8 -in myfile.input -out myfile.utf8
|
|
Perl is distributed with piconv. Usage is quite similar to (but in some ways more intelligent than)
GNU iconv. The man page for piconv provides details. piconv -l
provides a listing of over 120 recognized encodings, some of which are aliases of one another.
Convmv is a utility for converting file names in directory trees from one
encoding to another (for example, from a legacy encoding into a UTF-8 encoding). Only the file names are converted: file contents remain
unchanged. The man page for convmv may be found here.
For printing Unicode text or data files, there is uniprint
which is distributed with the Yudit package. Another, lesser-known utility is called
paps. If you are a developer, also take a look at
LASi, a C++ stream-based library for printing Postscript.
Uniprint is distributed with Yudit. While Yudit uses it for printing, it can also be used directly
from the command line. Usage can be obtained by typing:
uniprint --help
Typical usage is shown below:
|
uniprint -hsize <header_font_size> -font <truetype_font_to_use> -in <input_file>
-out <output_file>
|
% uniprint -hsize 0 -font /usr/local/fonts/cyberbit/cyberbit.ttf -in myfile.utf8 -out myfile.ps
|
|
Paps is a UTF-8-to-Postscript converter available from http://paps.sourceforge.net/doxygen-html/. Paps has options for printing in landscape, and for printing
multiple columns on one page which could be quite useful.
Also see the LASi Postscript printing library discussed below.
Because of the rapid maturation of Open Source software in the last few years, it is now
possible to enjoy a Linux desktop experience complete with high-quality, anti-aliased fonts rivaling
what is achievable on a Mac or Windows PC. Unicode fonts are naturally an important part
of creating an internationalized, multilingual desktop. To create such an environment, you need to know:
- How to install fonts, especially Unicode TrueType fonts, for use by X Windows.
- Some suggestions on which Unicode fonts to install.
These topics are covered below.
If you are running KDE in a recent distribution of Linux, the easiest way to install fonts is to use KDE's
graphical font installer which is part of the Control Center. From the KDE menu, select
Control Center, System Administration, and then Font Installer. To install fonts for everyone, click on
Adminstrative Mode and enter the root password.
Then simply click the Add button to add the fonts that you want (Fig. 9). When you are done, select Apply.
KDE will run all the scripts necessary to update your machine's font configuration.

|
|
Fig. 9. KDE's Font Installer makes it easy to install Unicode
TrueType fonts in Linux.
|
Modern Linux distributions use the fontconfig system for font management. Fontconfig periodically
scans font directories that are listed in the global /etc/fonts/fonts.conf and user-specific
~/.fonts.conf configuration files.
All users have to do is put new font files in one of the known directories and the fonts become automagically available for use.
This is much easier than it was in the old days!
For example, on SuSE Linux and many other systems that use the X windowing system, TrueType and OpenType fonts are stored in
/usr/X11R6/lib/X11/fonts/truetype. As this path is longer than I wish to remember, on systems that
I manage I take advantage of a symbolic link to simplify my life:
~> su
password: ******
~> cd /
~> ln -s /usr/X11R6/lib/X11/fonts/truetype/ /fonts
Now installing a new font for system-wide use from my home directory is nothing more than:
~> su -c "mv my_new_font.otf /fonts"
password: ******
And installing a font for personal use only is just:
~> mv my_new_font.otf .fonts
The Unicode Font Guide For Free/Libre Open Source Operating Systems
is a concise guide to free and legally downloadable vector (TrueType and OpenType) fonts
appropriate for use on Open Source operating systems. The Font Guide provides links to a selection
of high-quality Unicode fonts for most of the world's scripts encoded in Unicode.
For a more comprehensive treatment of fonts, including many commercial fonts which are not included
in the Unicode Font Guide mentioned above, see
Alan Wood's font pages.
Pfaedit is an Open Source font editor
for Linux/UNIX which allows you to
create your own Postscript, TrueType, OpenType, cid-keyed and bitmap (bdf) fonts.
You can also edit existing fonts and convert font files to different formats.
Even if you don't plan on
creating your own fonts, Pfaedit is extremely useful for determining which Unicode blocks, and hence which
scripts, are covered in a Unicode font. It is also indispensible for viewing the forms of glyphs before installing
a font. The font previews provided in KDE's font installer and other programs are usually completely inadequate
since generally only the ASCII or Latin blocks are shown. For non-Latin scripts, Pfaedit is much more useful
as a font preview program. For a quick preview of all glyphs in a font, be sure to select View -->
Compacted View. The default Encoded View will display cells for all Unicode code points, many of which
may be undefined in a given font.

|
|
Fig. 10. Pfaedit is an Open Source font editor for Linux.
|

|
The recently released Open Office
version 1.1 has excellent internationalization features, including
support for complex text layout (CTL), right-to-left (RTL), and bidirectional algorithm (BiDi) support.
Open Office also provides excellent support for Microsoft document formats, export to PDF, XML support, and
many other features.
Open Office localizations exist for many languages and locales, including
Czech,
Dansk,
Deutsch,
Español,
Français,
Hindi,
Italiano,
Japanese,
Nederlands,
Português,
Limba Romana,
Suomi,
Thai and
Türkçe.
|

|
IBM's Open Source International Components for Unicode
libraries provide robust Unicode services, including text handling, Unicode regular expression analysis,
language-sensitive collation, and data and formatting rules for over 200 locales. The libraries are available in C, C++, and Java.
Even if you don't plan to use the ICU libraries directly, the locale data by itself is an extremely useful resource. This is
an incredible resource that should not be overlooked!
|
Pango provides
an Open Source library for the layout and rendering of internationalized text.
Pango was started by Owen Taylor of Redhat in order to provide multilingual, Unicode-based
layout services for GTK+ and GNOME. Pango is not however dependent on GTK+ or GNOME and can
be used in other projects as well.
FreeType 2 is an open source font engine. It provides
an easy-to-use API to access font content in a uniform way, independent of the file format.
Client programs can access glyph outline data, or make use of the FreeType rasterizer to produce monochrome
or anti-aliased bitmaps.
An extremely interesting feature of the FreeType 2 library is that it contains an "autohinter" in order
to avoid infringing three patents owned by Apple Computer, Inc. If you have paid for a license from Apple, you can compile
FreeType so that it will use the patented font hinting technology. Fortunately for Linux, and for everyone else who doesn't want
to purchase a license from Apple, FreeType can also be compiled to use the "autohinter" which has been specifically crafted
to avoid infringing the patents while still producing acceptable bitmaps of glyphs at small pixel sizes.
|
LASi is a new Postscript printing library initially developed by a friend of mine,
Larry Siden and
now being maintained here on the eyegene web site.
It uses Pango and
Freetype2 for Unicode
text layout and glyph rendering.
It was designed primarily for use in scientific and other programs
(such as my program Madeline) which
need the ability to print scientific and other non-Latin symbols and scripts in Postscript
documents without being tied to large GUI application framework libraries like
QT, KDE, or GTK+/Gnome.
As shown in figure to the right and in the example below,
LASi provides a simple C++ stream-based API which
isolates the developer from the complex
details of printing Unicode text, including right-to-left scripts
(Hebrew, Arabic) and scripts which have
complex shaping rules (Arabic, Thai, Devenagari). In addition
to world scripts, users can of course also take advantage of
the numerous scientific and mathematical symbols defined in
Unicode by simply supplying UTF-8-encoded strings to the
show() method.
|

|
|
Fig. 11. The LASi C++ PostScript stream library
makes it trivially easy to incorporate Unicode-based text
into your PostScript documents.
|
|
|
|
LASi Postscript printing library example
|
#include <iostream>
#include <stdexcept>
#include <psDoc.h>
using namespace LASi;
using namespace std;
int main(const int argc, char* const argv[])
{
try {
PostscriptDocument doc;
doc.osBody() << "100 300 translate\n" ;
doc.osBody() << setFont("sans") << setFontSize(72) << show("foobar");
doc.osBody() << "10 0 translate\n" ;
doc.osBody() << setFont("sans") << setFontSize(72) << show("שלום");//shalom
cerr << "doc.write(cout);\n";
doc.write(cout);
} catch (runtime_error& e) {
cerr << e.what() << endl;
return 1;
}
return 0;
}
|
Output:
|

|
|
|
You can now find out more about LASi and obtain Up-to-date versions
of the library from
http://unifont.org/lasi/.
