A crowd-sourced multimedia dictionary app of modern Nahuatl variants
for smartphones
Edward H. Trager
March, 2020
INITIAL DRAFT (ENGLISH) UPLOADED 2020.06.29
Yoltok totlahtol, wan yeka tohwantih tiyoltokeh. Kemah mikis totlahtol, nohkia poliwis tonemilis wan poliwis tonelwayo.
Our Nahuatl language is alive, and therefore we also are alive. When our language dies, our roots and our way-of-life will also disappear.
Está viva nuestra lengua, y por eso nosotros estamos vivos. Cuando nuestra lengua muera, también desaparecerán nuestra historia y nuestra raices.
— Rafael Nava Vite, Nahua writer from la Huasteca1
Nahuatl is an endangered language
Ethnologue estimates that 40% of the world’s languages are now endangered.2 Nahuatl, the lingua franca of the historic Aztec Empire, is one of these endangered languages.
In Mexico today, there are currently somewhere between 1.5 million3 and 1.7 million4 speakers of Nahuatl, making Nahuatl the most widely spoken indigenous language in Mexico. Those numbers might lead one to believe that the language is not endangered. However, Olko and Sullivan assert that Nahuatl is indeed very much in danger of extinction. They suggest that the ideological policies of Hispanicization —castellanización— that began after the Mexican Revolution especially contributed toward the conflictive and racist attitudes against indigenous language speakers that we see in Mexico today. They and other researchers, such as Rolstad, note that Nahuatl speakers themselves often share negative attitudes toward use of their own language.5, 6
Increasing pressures in indigenous communities due to patterns of modernization, internal migration to urban areas, and climate change are also accelerating shifts in language use especially among younger generations of Nahuatl speakers. Between 1970-1990, emigration from the five most populous Nahuatl-speaking states exceeded 1.5 million people per decade.6 Most of these people move to urban centers in Mexico or in the United States, where Spanish or English is the dominant language and where Nahuatl has much less utility than it did in their home communities.
A number of different variants7 of Nahuatl coexisted in different parts of Mexico and Central America at the time of conquest in the 1500s.8 Una Canger provides evidence that the variant of Tlaltelolco/Tenochtitlan —which she terms Urban Nawatl— was just one of a number of variants, and that this urban koiné developed when speakers of many varieties of Nahuatl from different parts of the Aztec empire found themselves communicating face-to-face in the famous capital and surroundings in the Valley of Mexico.9
After the conquest by the Spanish, Nahuatl initially blossomed as an administrative and literary language. In 1570, King Philip II of Spain made Nahuatl an official language of the colonial administration in New Spain and numerous important literary and historical texts were composed in Nahuatl during the 16th and 17th centuries.
However after Charles II of Spain banned the use of indigenous languages throughout the Spanish colonial empire in 1696, the use of Nahuatl as an administrative language ended, use as a prestige literary language began to decline, and communities of Nahuatl speakers became more isolated.
Geographic isolation provided ample opportunity for the existing variants of Nahuatl to continue to evolve independently and diverge further from one another. Nevertheless, 500 years after conquest, there remains a high degree of mutual intelligibility among many modern variants10, even in some cases between variants that are geographically widely separated.11
Autochthonous developments and opportunities in the modern world
While the modern world presents numerous challenges to the vitality of indigenous languages in general, it also provides many opportunities for new and creative responses. With global smartphone penetration now surpassing 40%12, one of the most interesting things we are now seeing is the autochthonous development of language and community-building resources within indigenous communities themselves. Many of these are quite simple —in the sense that they rely entirely upon readily-available existing tools— and yet these responses can be quite effective at building community and sharing relevant information across wide geographic areas.
For example on WhatsApp, a group called NÁHUATL founded by a Native Nahuatl language teacher in Mexico City, Mtro. Agustín Camargo, now has over 150 members, primarily from many different places in Mexico. The group also includes Pipil speakers from El Salvador, people from the United States, Argentina, Costa Rica, France, and Italy. Some of these people are native speakers, some are heritage speakers, and others are simply hoping to improve whatever Nahuatl they have learned or picked up so far. At the same time, the group has witnessed fruitful cross-variant exchanges, for example between speakers of variants of Nahuatl in Mexico and speakers of Pipil in El Salvador.13 Pipil —called Nawat by speakers of the language— is a highly endangered variant of Nahuatl being revitalized in El Salvador. These exchanges suggest that there is very great interest among native speakers of many variants of Nahuatl to share what they know with others in this new and burgeoning online community.
On Facebook, a group called Nawatlahtolli has over 6,000 members who actively exchange all manner of information and resources related to Nahuatl14. Another Facebook group with over 2,700 followers, Timumachtikan Nawat —which literally translates as let’s learn Nawat— provides information and excellent short videos for learning Nawat15. The author, Héctor Martínez, also maintains a YouTube channel.
Because of this demonstrable increase in interest, we believe the time is now especially ripe to empower native Nahuatl speakers, heritage speakers and non-native language learners by building a modern online crowd-sourced multimedia dictionary that will give Nahuatl a firm footing for survival in the modern world.
Proposal: a crowd-sourced multimedia Nahuatl dictionary for the modern world
We propose the creation of a crowd-sourced, carefully curated and vetted multimedia dictionary app of modern Nahuatl variants that will help native speakers, heritage speakers, and non-native speakers to learn one or more variants of Nahuatl.
Our vision is to allow native speakers of all varieties of Nahuatl from Mexico and other parts of Central America —including Nawat speakers from El Salvador— to contribute entries to this new dictionary by using their smart phones. With time, we expect this dictionary to become increasingly comprehensive and authoritative.
In addition, we envision this app as an important tool for indigenous rights activists in the struggle to revitalize their languages and preserve their local cultures against the onslaught of hegemonic cultural and state colonialities. We hope that this app will help communicate indigenous narratives and worldviews on living and being through their own words.
As in a traditional dictionary, an entry begins with a word. However, that is where the similarity with a traditional dictionary ends. The structure of the app will be optimized to allow users to easily attach supplementary entries to any basic word entry. These supplementary entries will take various forms —all discussed below— and will be key in greatly enhancing the utility of this online dictionary.
Tagged entry architecture
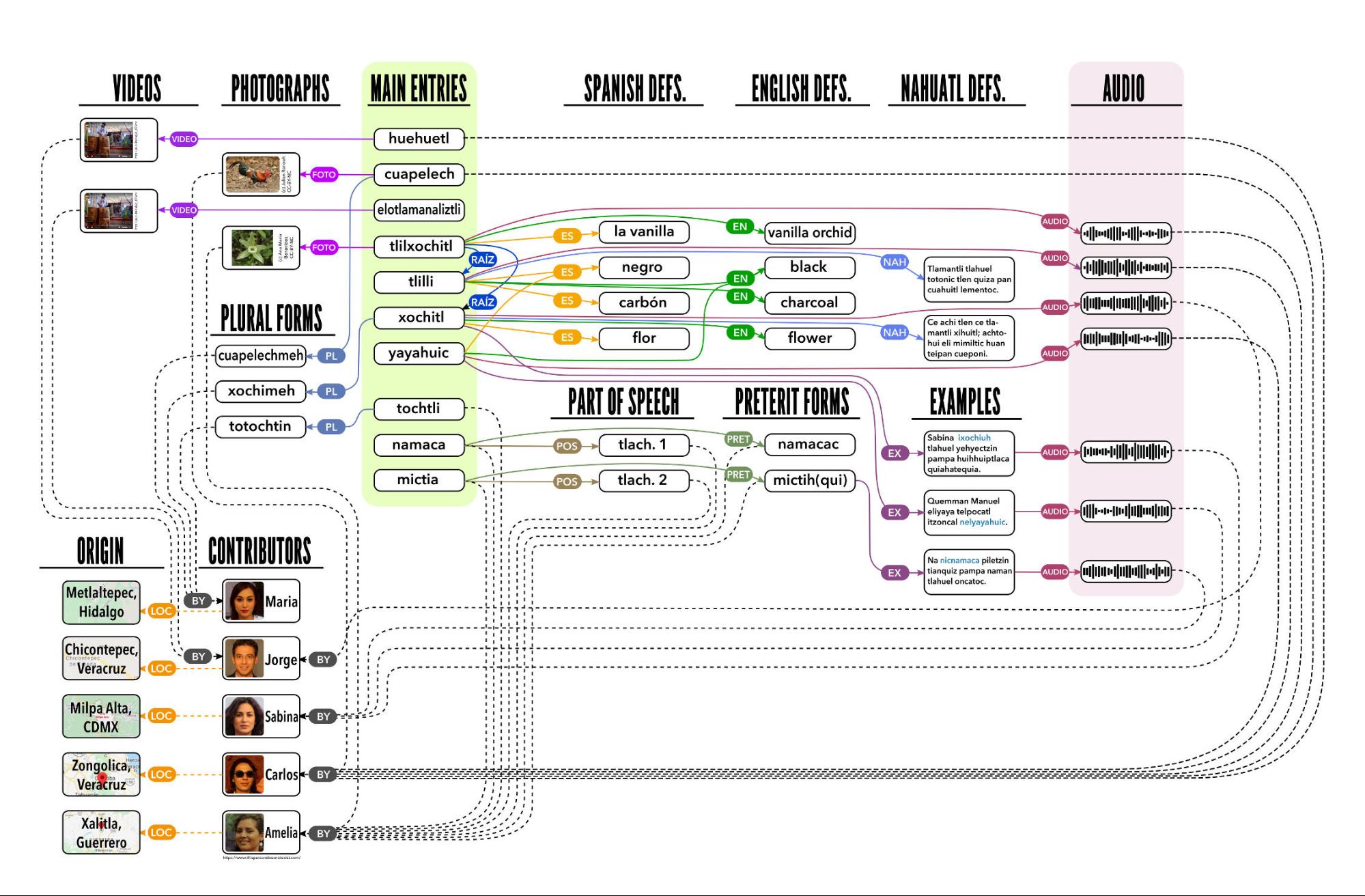
In order to make this online dictionary as flexible and as useful as possible, a well-designed architecture is essential. We plan to implement an architecture built around the concept of an expandable set of tags (figure 1).
Figure 1. Schematic diagram of the tagged-entry architecture for the dictionary app. Main entries are connected by tags and dotted lines to supplementary entries for definitions in various languages, pronounciations, grammatical forms, example sentences, photographs, videos, etc. In addition, all entries are tagged according to who contributed the entry and that person’s region of origin.
Every entry in the dictionary will have one or more tags associated with it. A primary word entry will be tagged as a word_entry, while an audio recording associated with that primary entry will —not surprisingly— merit an audio tag. Any definitions associated with the word will be tagged as definition. Definitions may be written in different languages. So, these definitions will further be tagged according to the language of the definition: Nahuatl, Spanish, English, etc.
The initial set of tags will include word_entry, definition, Nahuatl, Spanish, English, root, plural_noun_form, preterit_verb_form, audio and video, among others. The app will know how to handle each type of tagged entry. A beautiful aspect of this design is that new tags can be added to the system as the data grow in the future.
For example, if someone wants to add French definitions to the dictionary, we need only add a French tag. In most cases, no other changes to the core app will be necessary, as the app will already know how to handle definitions, and French definitions are simply definitions in one additional language. Once a few French definitions have been submitted, vetted and published, they will automatically appear in the definitions section under the relevant word entries.
Further below we describe different entry types in more detail.
Vetting entries
An editorial board consisting of native speakers of different variants of Nahuatl will be responsible for vetting all submissions and will have final say regarding the publication of submissions. A public voting system will also be included to assist users and the editorial board alike. Editors will receive a stipend for their work.
Audio recordings of pronunciations and example sentences
A single word in Nahuatl may be pronounced differently by speakers from different regions. For example, the common word calli (house) is pronounced with a geminated or lengthened ell sound, /kálːi/, in Nahuatl of the Huasteca region, but in Nahuatl in the state of Guerrero, an aspirated h sound precedes the ell sound, /káhli/16.
We believe having a compendium of different pronunciations accessible from one’s smartphone will be extremely useful to everyone. To this end, users who have registered and been vetted as native speakers will be able —and will be encouraged— to record the pronunciation of words and provide spoken example sentences in their native variants directly from their smart phones.
While any user will have the ability to upload voice recordings for their personal use on their private account, only verified voice recordings from vetted native speakers will become part of the publicly-visible data resource that everyone will be able to listen to.
Entries of grammatical forms
Native contributors from different regions will also be encouraged to create grammatically-tagged entries. Initially we will focus on illustrating plural forms (for nouns) and preterit forms (for verbs), as these two are especially important to know in Nahuatl. These are described in more detail below.
After the initial implementation is complete, it will be possible to add additional tags to cover additional grammatical forms —such as full conjugations of verbs. The tagged entry structure described previously will allow for this and other expansions of scope with zero changes to the foundational architecture.
Plural noun forms
A turkey is tōtolin, and many turkeys are tōtolmeh, but my turkeys are notōtolhuan. Prefixes and suffixes are used to denote differences between singular and plural and between possessive and non-possessive forms in this language. Differences may also occur depending on whether a noun is animate or inanimate. Plural forms may vary both within and among variants of Nahuatl —as well as over time— in ways that are not obvious. Displaying known plural forms and variants within the online dictionary will greatly help to clarify common and regional usage patterns.
Preterit verb forms
Is the past-tense form of the verb mictia (to kill) mictih or mictihqui? Both may be correct. Preterit forms are largely determined by the verb class to which a verb belongs, but it is not uncommon for there to be two valid preterit forms of a verb within a single variant. There may also be differences in preterit forms between different variants of Nahuatl. Including preterit verb form entries in the initial implementation will increase the overall utility of word entries in the app.
Visual media entries
All registered users will also be able to submit photographs and video clips as supplementary material supporting an entry. Photographs can be quite valuable in insuring the accurate identification of plants and animals, especially in the case of endemic species. Video clips can be useful to showcase aspects of local cultural activities, food preparation, customs, or ceremonies. As with any submission, a vetting process will be used to deter hackers and to insure that the publicly-visible data are accurate and authentic.
Geography is important
The user registration process will include a declaration of home community, municipality, and state. In this way, the app will be able to automatically tag and track entries by region of origin.
Earlier we saw that there exist regional differences in the pronunciation of the word calli (house). Audio recordings submitted by individual users will be automatically tagged to their region of origin and all users will be able to see origin information when listening to submissions. This will help native and non-native speakers alike.
Linking to root words
Understanding the underlying origin of words is immensely helpful when trying to learn and retain new and unfamiliar vocabularly in any language. As in other languages, longer words in Nahuatl are often constructed from shorter roots.
Take the Nahuatl word mētz·cua·lo as an example. The word derives from mētz·tli, moon, and cua, the verb to eat. At the end, we have -lo, signifying a passive construction: eaten. Once we know that this word literally means the moon is eaten, it is easy to remember that this refers to a lunar eclipse.
Because understanding word origins is crucial to gaining a deeper understanding of the language, the app will be designed in a way that facilitates linking word entries to their constituent roots. Clicking on hyperlinks will take the user to the full entries of the root words.
Capturing regional differences in vocabulary
In La Huasteca region, piyali is a common greeting when meeting people. In some other regions of Mexico, panolti is used instead. To capture regional differences in word usage, entries will also be able to be linked to other words having the same or a very similar definitions or meanings. Naturally, users will be able to look up Nahuatl words matching a specific definition or closely-related definitions in Spanish, English, or any other available language (reverse lookup).
Adding definitions to word entries
Users will also be able to add definitions to word entries. The definitions themselves will be tagged by language, so that a single word can easily have a definition in Nahuatl, Spanish, English, French, Chinese, or in any other language.
Automatic orthographic conversion in real time
Several distinct orthographies of Nahuatl are in common use. There is no single standardized orthography. As these orthographies are phonetic in nature, it is to a large extent possible to computationally convert a spelling in any one orthography to any other orthography. We have developed a proof-of-concept tool that can convert among several of the most popular Nahuatl orthographies in real time17. This tool is also already quite tolerant of variant spellings so that users need not have perfect spelling to use the tool. The dictionary app that we are proposing will be built from the ground up with a refined version of this tool tightly integrated into the processing pipeline.
Users will have the ability to perform word searches and display results in at least three commonly-used Nahuatl orthographic systems: (1) the Andrews-Campbell-Karttunen (ACK) system which is closely based on the colonial-era “classical” orthographies originally introduced by Spanish friars; (2) the Secretaría de Educación Pública (SEP, Ministry of Public Education) system developed in collaboration with Instituto Lingüístico de Verano (Summer Institute of Linguistics (SIL)), and (3) the Hasler Modern system, an adaptation of the SEP system that closely reflects “intuitive” spellings often seen in online settings.
We believe this orthographic conversion technology will go a long way toward eliminating one of the biggest obstacles that native Nahuatl speakers face when reading Nahuatl written by people from different regions or from historical time periods. It will also has the potential to largely eliminate the issues that Nahuatl speakers currently face when searching existing online resources, as those resources are only available in one orthography.
Incorporation of IDIEZ data
The Instituto de Docencia e Investigación Etnológica de Zacatecas (IDIEZ)18 was founded as a project for Nahuatl language revitalization. At IDIEZ, a number of native Nahuatl teachers and researchers from La Huasteca region of Mexico work on education, research, and language revitalization projects in collaboration with both Mexican and international researchers.19 In 2016 IDIEZ, in collaboration with the University of Warsaw’s Faculty of “Artes Liberales”20 , published the first comprehensive monolingual dictionary of modern Huastecan Nahuatl.21 This dictionary contains entries for nearly 11,000 words. In addition to the dictionary, IDIEZ has also produced a glossary of over 6,700 words for students —representing slightly over 60% of the entries from the monolingual dictionary— with both Spanish and English translations, and has recorded nearly 2,000 audio files of word pronunciations.
With permission from IDIEZ, we would like to use the IDIEZ data as the “starter” data for this new project.
Making a smartphone automatically recognize Nahuatl
Automatic Speech Recognition (ASR) is an umbrella term for digital technologies that allow devices such as computers and smartphones to directly transcribe human speech into written text. In recent years, ASR systems using artificial neural network technologies —collectively called deep learning— are now becoming accurate enough to use in production systems.
Over the last few years, the Machine Learning Group at Mozilla has been working on DeepSpeech22, an ASR system with a simple application interface (API) that can easily be used by software developers. DeepSpeech builds on a number of ideas presented in Baidu’s Deep Speech research paper from 201423 and uses Google’s TensorFlow24 technology to simplify implementation. In conjunction with DeepSpeech, Mozilla also began a project called CommonVoice25 that aims to provide voice training sets in numerous languages so that developers all over the world can teach machines to transcribe human speech into written text. While numerous other groups are also working on ASR technologies, Mozilla’s DeepSpeech and CommonVoice projects are Open Source projects that can be freely used by anybody.
Recently we have been experimenting with training a DeepSpeech network to automatically transcribe Nahuatl speech into text. Our goal is to eventually be able to use DeepSpeech for real-time transcription within our app. As previously mentioned, there is no single standardized orthography for Nahuatl, and Nahuatl speakers from different regions are familiar with different orthographies for transcribing Nahuatl. If we can train DeepSpeech to efficiently and accurately transcribe Nahuatl for users of our app, we will be able —to a substantial degree— to eliminate the problem of multiple orthographies, because our app will know the correct spelling of words in at least three of the most widely-used orthographies for Nahuatl. Users will not need to be experts in multiple Nahuatl orthographies when contributing or searching for entries in the app.
From late January through mid-February of 2020, we experimentally trained a DeepSpeech network to transcribe Nahuatl words in IDIEZ’s audio corpus and write them out in a special orthography that we use internally in our orthography conversion engine. In this way, our orthography engine can directly spell the words out in any of the three common orthographies that we are targeting for use within our app. After training on a set of 2,848 audio clips of individual words, we tested the network against 160 words that the network had never seen before and obtained a word error rate (WER) of 6.25%. This is a very good result for a small training corpus trained for a limited time.
Our initial experiments with automatic recognition of Nahuatl speech show promise. With funding, more data and more training time, we are confident that we can usefully incorporate automatic speech recognition along with our orthography engine into the proposed app to benefit users (figure 2).
Figure 2. Automatic speech recognition combined with our orthography conversion engine would assist users in creating correctly-spelled entries without needing to be experts in the multiple orthographies in which modern Nahuatl is commonly written.
Comparison with other projects
Several other online Nahuatl dictionary projects merit a comparison with what we are proposing here:
University of Oregon Nahuatl Dictionary. For many years now, Dr. Stephanie Wood, director of the Wired Humanities Projects at the University of Oregon, has been working on an online dictionary of Classical Nahuatl.26 This is a very valuable resource for students and scholars of Classical Nahuatl of the colonial-era of Mexico. A few years ago, Dr. Wood, in collaboration with IDIEZ, incorporated a number of entries of modern Huastecan Nahuatl into her project. A number of these entries include audio pronunciations from IDIEZ as well. Excepting the data from IDIEZ, the Oregon project remains primarily focused on Classical Nahuatl of the colonial era of Mexico.
UNAM Gran Diccionario Náhuatl. The online Gran Diccionario Náhuatl27 at the Universidad Nacional Autónoma de México represents the continuation and expansion of years of work by Marc Thouvenot of the Centre National de la Recherche Scientifique (CNRS, France) and collaborators at the Instituto de Investigaciones Bibliográficas and the Instituto de Investigaciones Históricas at UNAM. This project is solidly focused on Classical Nahuatl of the colonial era of Mexico.
Talking Dictionaries of the Living Tongues Institute for Endangered Languages. The Living Tongues Institute for Endangered Languages28 has worked with indigenous collaborators to create a a number of “talking dictionaries”29. These dictionaries can be accessed from a smart phone. The smartphone app provides the ability to add pronunciations and can also be used offline when no internet connection is available. Indigenous collaborators have created a Pipil (Nahuat) Talking Dictionary30. This Pipil dictionary currently has a total of 162 terms, most of which are nouns. There are no examples showing usage in context or grammatical features, and the paucity of verbs limits the utility of this resource.
Among the three projects mentioned above, two (Oregon, UNAM) are solidly focused on Classical Nahuatl of colonial-era Mexico. The Oregon and UNAM projects were not originally conceived with mobile device access in mind. A recent technological upgrade now makes the Oregon dictionary usable on mobile devices, even though the dictionary is not completely optimized for mobile access. The UNAM project on the other hand does not appear to have any mobile design features at all.
The Living Tongues Institute’s Talking Dictionary app platform does hold promise. The current platform is designed for use on smart phones and mobile devices, includes audio pronounciations, and has an offline mode available for working in areas with little or no internet. However, Living Tongues Institute does not appear to currently have any dictionaries of Nahuatl spoken in Mexico. While they do have an incipient Pipil (Nawat of El Salvador) dictionary, the Pipil project has fewer than 200 entries and the number of entries has not increased in many months.
It is not surprising that crowd sourcing (“colaboración masiva”) has not been used in the Oregon or UNAM projects which are focused on Classical Nahuatl, a historical language. The Living Tongues Institute does strive to collaborate with indigenous speakers, but does not appear to have designed their Talking Dictionary app with massive collaboration in mind.
We believe that our project will be the first to incorporate massive online collaboration by indigenous speakers as a core design principle and powerful tool for indigenous language revitalization, while also actively tracking regional and dialectical differences.
Model and platform for other threatened and endangered languages
We believe that our unique crowd-sourced approach can also serve as a model and platform for other threatened and endangered languages. In Mexico alone, there are many other indigenous languages besides Nahuatl that are spoken in regionally dispersed and historically isolated areas. As anyone who has travelled in rural Mexico in the last few years knows, WiFi antennas have been springing up like mushrooms after rain in numerous little towns all over Mexico, and an increasing number of rural people now have access to low-cost smart phones. We believe that our crowd-sourced modern Nahuatl app for smart phones may serve as a model for other indigenous language communities in Mexico and beyond. We are at a unique point in history where access to modern technology has, on the one hand, the potential to accelerate the demise of indigenous languages or, on the other hand, the potential to insure that all of our mother languages survive and flourish as part of our shared humanity. Which will it be?
========================
References
1. Vite, Rafael Nava, 2016. Toapah Wahki: La tierra ya no se moja, p. 18. Programa de Desarrollo Cultural de la Huasteca. 138 pp. ISBN: 978-607-9248-95-6. English translation of the quotation by me.
2. How many languages are there in the world?
https://www.ethnologue.com/guides/how-many-languages
3. Nahuatl page, Endangered Language Alliance
http://elalliance.org/languages/meso-america/nahuatl/
4. 1,725,620 hablantes de náhuatl de 3 años y mas. Lenguas indígenas en México y hablantes (de 3 años y más) al 2015. http://cuentame.inegi.org.mx/hipertexto/todas_lenguas.htm
5. Olko, Justyna & Sullivan, John, 2014. Toward a Comprehensive Model for Nahuatl Language Research and Revitalization. Proceedings of the Fortieth Annual Meeting of the Berkeley Linguistics Society, Feb. 7-9, 2014, pp. 369-397. University of California, Berkeley. ISSN: 0363-2946.
6. Rolstad, Kellie, 2001. Language Death in Central Mexico: The Decline of Nahuatl and the New Bilingual Maintenance Programs. Bilingual Review / La Revista Bilingüe, Vol. 26, No. 1 (January 2001-April 2002), pp. 3-18.
7. I use the term “variant” here in lieu of “dialect” because “dialect” carries pejorative connotations in some contexts.
8. Canger, Una, 1988. Nahuatl dialectology: a survey and some suggestions. IJAL, Vol. 54., No. 1 (Jan., 1988), pp. 28-72.
9. Canger, Una, 2009. El nauatl urbano de Tlatelolco/Tenochtitlan, resultado de convergencia entre dialectos, con un esbozo brevísimo de la historia de los dialectos. A brief version of this article was presented at the symposium, Variación y cambio morfosintácticos: ¿Evolución interna o cambios introducidos por contacto lingüístico? Perspectiva funcional tipológica. 53rd Congreso Internacional de Americanistas, Mexico City, 2009.
10. Wright, David, 2000. Response on Linguist List to a question about mutual intelligibility among Nahuatl variants. http://listserv.linguistlist.org/pipermail/nahuat-l/2000-May/001038.html
11. Wright Carr, David Charles, 2016. Lectura del Náhuatl, versión revisada y aumentada. Instituto Nacional de Lenguas Indígenas (INALI), Mexico, 2016. 488 p. ISBN 978-607-8407-21-7.
https://site.inali.gob.mx/publicaciones/libro_lectura_nahuatl/pdf/lectura_del_nahuatl.pdf
12. Statista. (October 25, 2019). Global smartphone penetration rate as share of population from 2016 to 2020 [Graph]. In Statista. Retrieved December 11, 2019, from https://www.statista.com/statistics/203734/global-smartphone-penetration-per-capita-since-2005/
13. Trager, Edward Harben, 2019. Unpublished research.
14. Nawatlahtolli. Facebook group page, accessed December 24, 2019. https://www.facebook.com/groups/nahuatlahtolli/
15. Martínez, Héctor Josué. Timumachtikan Nawat. Facebook group page, accessed December 24, 2019. https://www.facebook.com/TimumachtikanNawat
16. SIL Mexico Guerrero Nahuatl page. Pronunciation of calli in Guerrero Nahuatl:
https://mexico.sil.org/sites/mexico/files/kahli.wav. Web page and audio resources accessed February 04, 2020.
https://mexico.sil.org/language_culture/aztec/nahuatl-ngu.
17. Trager, Edward Harben, 2019. Proof-of-concept tool to automatically convert among Nahuatl orthographies in real time. https://unifont.org/convert/.
18. Instituto de Docenia e Investigación Etnologica de Zacatecas (IDIEZ) web site. Web page accessed February 12, 2020.
19. Sullivan, John. 2001. The IDIEZ Project: A Model for Indigenous Language Revitalization. Collaborative Anthropologies, Vol. 4 (2001), pp. 139-153. Doi: 1943-2550
20. Wydział “Artes Liberales”, Uniwersytet Warszawski (Faculty of “Artes Liberales”, University of Warsaw). Web page accessed February 13, 2020. http://al.uw.edu.pl/en/.
21. Sullivan, John et. al. 2016. Tlahtolxitlauhcayotl. A monolingual dictionary of Modern Huastecan Nahuatl, Chicontepec, Veracruz. Zacatlan Macehualtlallamiccan (IDIEZ) and University of Warsaw Faculty of “Artes Liberales”. 627 pp. Doi: 978-83-63636-51-7. ISBN: 978-83-63636-51-7.
https://www.academia.edu/34987634/Tlahtolxitlauhcayotl._Chicontepec_Veracruz.
22. Mozilla Foundation. DeepSpeech project. https://github.com/mozilla/DeepSpeech.
23. Hannun, Awni et. al. 2014. Deep Speech: Scaling up end-to-end speech recognition. Baidu Research – Silicon Valley AI Lab. arXiv:1412.5567v2 [cs.CL] 19 Dec 2014. https://arxiv.org/abs/1412.5567 .
24. TensorFlow. An end-to-end open source machine learning platform. https://www.tensorflow.org/.
25. Mozilla Foundation. CommonVoice project. https://voice.mozilla.org/.
26. Wired Humanities Project Nahuatl Dictionary at the University of Oregon. https://nahuatl.uoregon.edu/
27. Gran Diccionario Náhuatl, Universidad Nacional Autónoma de México Instituto de Investigaciones Bibliográficas y Instituto de Investigaciones Históricas. http://www.gdn.unam.mx/.
28. Living Tongues Institute for Endangered Languages. https://livingtongues.org/
29. Talking Dictionaries project. https://talkingdictionaries.app/
30. Pipil (Nahuat) Talking Dictionary. https://talkingdictionaries.app/pipil/overview
=================
END
=================
